《MySQL DBA修炼之道》——3.7 字符集和国际化支持
本文共 4455 字,大约阅读时间需要 14 分钟。
本节书摘来自华章出版社《MySQL DBA修炼之道》一书中的第3章,第3.7节,作者:陈晓勇,更多章节内容可以访问云栖社区“华章计算机”公众号查看
3.7 字符集和国际化支持
3.7.1 什么是字符集
字符集(character set)是一套符号和编码。校对规则(collation)是在字符集内用于比较字符的一套规则,即字符集的排序规则。假设我们有一个字母表使用了4个字母:'A'、'B'、'a'、'b'。现在为每个字母赋予一个数值:'A'=0,'B'= 1,'a'= 2,'b'= 3,字母'A'是一个符号,数字0是'A'的编码,那么这4个字母和它们的编码组合在一起就是一个字符集。我们可以认为字符集是字符的二进制的编码方式,即二进制编码到一套符号的映射。对于字符集,MySQL能够做如下这些事情。使用多种字符集来存储字符串。使用多种校对规则来比较字符串。?在同一台服务器、同一个数据库甚至在同一个表中,使用不同的字符集或校对规则来混合字符串。允许定义任何级别的字符集和校对规则。可使用SHOW CHARACTER SET语句列出可用的字符集。mysql>SHOW CHARACTER SET;可使用SHOW COLLATION语句列出utf8字符集的校对规则。mysql>SHOW COLLATION LIKE 'utf8%';3.7.2 国际化支持因为现存编码不能在多语言电脑环境中使用,而且字符数有局限。所以诞生了Unicode(统一码、万国码、国际码、单一码)。Unicode是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。一个字符的Unicode编码是确定的,但Unicode的实现方式不同于编码方式。在实际传输过程中,由于不同系统平台的设计不一定都是一致的,且出于节省空间的目的,对Unicode编码的实现方式也有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,UTF)。这其中有一种UTF-8编码,它是一种变长编码,MySQL中经常使用的utf8字符集就是UTF-8 编码。UTF-8编码的思想是不同的Unicode字符采用变长字节序列编码:基本拉丁字母、数字和标点符号使用一个字节。大多数的欧洲和中东手写字母适合两个字节序列。韩语、中文和日本象形文字使用三个字节序列。utf8是MySQL存储Unicode数据的一种可选方法,MySQL还有其他的存储Unicode数据的字符集,这里就不做额外介绍了。 
mysql> SHOW CHARACTER SET; 列出可用的校对规则可使用如下语句。 mysql> SHOW COLLATION 更低级别的配置会继承更高级别的配置。例如,如果创建一个数据库,不指定字符集,那么它会继承服务器级的默认字符集。 对于生产环境的升级脚本,建议在表级别指定默认的字符集,以避免歧义或继承了错的数据库默认字符集。 2.控制server端和client端交互通信的配置 绝大部分MySQL客户端都不具备同时支持多种字符集的能力,每次都只能使用一种字符集。客户和服务器之间的字符集转换工作是由如下几个MySQL系统变量来控制的。 character_set_server:MySQL Server默认字符集。 character_set_database:数据库默认字符集。 character_set_client:MySQL Server假定客户端发送的查询使用的字符集。 character_set_connection:MySQL Server接收客户端发布的查询后,将其转换为character_set_connection变量指定的字符集。 character_set_result:MySQL Server把结果集和错误信息转换为character_set_result指定的字符集,并发送给客户端。 图3-13说明了字符集的转换过程。 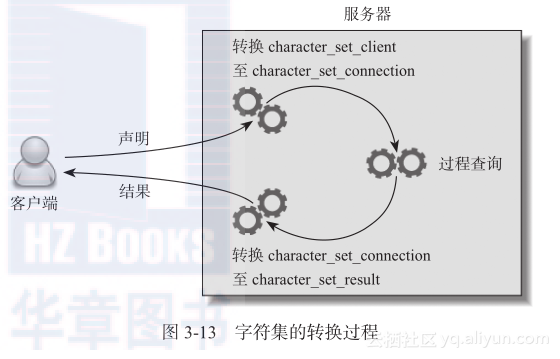
mysql> SET character_set_client = x; mysql> SET character_set_connection = x; mysql> SET character_set_results = x; 再来看看SET CHARACTER SET x语句,它等同于下面这3条语句。 mysql> SET character_set_client = x; mysql> SET character_set_results = x; mysql> SET collation_connection = @@collation_database; 有些客户端命令支持“--default-character-set”选项,此选项允许用户连接时设置字符集。它等同于以下这3条语句。 mysql> SET character_set_client = x; mysql> SET character_set_connection = x; mysql> SET character_set_results = x; 如果数据库服务器中有很多数据库使用不同的字符集,且有各种不同语系的客户端,很复杂,那么使用init-connect=SET NAMES binary是一种可以考虑的方式。这个指令的目的是让clinet与server交互的时候以as-is 模式(是什么就是什么,不做任何转换)来传送。 索引可用来排序,但如果指定了用其他的非默认排序规则,那么将不能利用索引进行排序,比如在下面的语句中: EXPLAIN SELECT col_1,col_2 FROM table_name ORDER BY col_2 COLLATE utf8_bin ```col_2字段使用的是utf8字符集,且其上有索引,默认的utf8字符集的排序规则是utf8_general_ci,而上面的案例指定的是用utf8_bin进行排序,那么EXPLAIN输出可以看到有filesort(文件排序),即没有利用到索引进行排序。同理,如果连接两张表使用的连接列不是一样的字符集,那么也不能利用索引,因为必须先执行转换工作,可用EXPLAIN EXTENDED先进行确认。默认情况下,MySQL的字符集是latin1(ISO_8859_1)。latin1字符集是单字节编码,应用于英文系列,最多能表示的字符范围是0~255(编码范围是0x00~0xFF),其中0x00~0x7F之间和ASCII码完全一致,因此它是向下兼容ASCII的。latin1字符有限,如用来存储中文、日文、韩文、希伯来文等语言时往往会导致乱码,为了避免乱码,支持国际化,个人建议是生产环境都统一使用utf8字符集,除非你有特殊理由。以下是关于在生产环境中使用utf8字符集的一些说明和注意事项。1)为什么生产环境中建议使用utf8字符集?主要是为了维护和开发都方便。大家都统一使用utf8字符集,将一劳永逸地避免各种乱码问题。一个数据库如果存在各种字符集,就会很容易出错,也会大大提高开发的难度。国际化支持也是使用utf8字符集的一个考虑。当然,utf8字符集也有弊端,主要就是空间的消耗。比如,对于CHAR(10),将需要用到30个字节来存放。对于VARCHAR(10),则是按照字符串的长度来存储的,虽然不存在过多的磁盘空间消耗,但MySQL内部实现的一些数据结构,如临时表需要分配最大可能的长度,也可能导致内存大大增加。更多的空间还意味着更差的I/O性能。有时,我们可能为了节省空间(如果空间真的是一个需要考虑的因素)而选择其他字符集(如用GBK存储汉字),对于大批量的机器,特定的服务选择特定的字符集,这种情况下所节省的空间也是很可观的,但对于一般的中小型公司,建议统一使用utf8,一劳永逸地解决乱码问题是更明智的选择。2)如何判断多字节字符集的字符串长度?LENGTH()返回值为字符串的长度,单位为字节。一个多字节字符算作多字节。CHAR_LENGTH()返回值为字符串的长度,长度的单位为字符。一个多字节字符算作一个单字符。例如:对于一个包含了5个二字节的字符集,LENGTH()返回值为10,而CHAR_LENGTH()的返回值为5。3)有时创建索引的时候,可能会提示出错。MySQL会假定每个字符有3个字节,由于索引长度有限制,那么创建索引的时候,可能会提示下面这样的错误。``ERROR 1071 (42000): Specified key was too long; max key length is 1000 bytes``这时需要明白,自己创建的是多字节字符集,字节数实际上超过1000了。4)UTF-8 是可变长度的编码,使用1到4个字节来存储。但MySQL 5.1及以前的版本,对UTF-8的支持并不彻底,它的utf8只是3字节字符集,有些文字符号是不能存储的,如 emoji表情。MySQL5.5增加了字符集utf8mb4(4-Byte UTF-8 Unicode Encoding),可以存储一些MySQL utf8不能存储的字符,需要留意的是,设置了utf8mb4字符集后,需要重启MySQL Server才能生效。
转载地址:http://zapvl.baihongyu.com/
你可能感兴趣的文章